
Julien Colin
ELLIS PhD Student in Interpretable AI, ELLIS Alicante - Brown University
Hi, my name is Julien. I am a 4th year ELLIS PhD student, working under the supervision of Nuria Oliver and Thomas Serre.
I study what makes representations interpretable to humans, how aligning models with human perception reshapes their representations, and how we can leverage this to steer models toward more interpretable representations.
If any of these questions interest you, feel free to reach out for a chat!
Feature visualization comparisons are available on larger screens to keep the mobile homepage fast and stable.







































News
Research (selected)

Capability ≠ Interpretability: Human Interpretability of Vision Foundation Models
Which modern vision models learn the most interpretable features? We introduce a human-centric framework for measuring and comparing interpretability through two psychophysics protocols: localizability (can people predict where a feature fires?) and nameability (can people describe what it represents?). Applying it to ~6,000 sparse autoencoders features from six vision transformers, we collect more than 15,000 responses from about about 440 participants and find that foundation models (DINOv2, DINOv3, CLIP, SigLIP) are consistently less interpretable than their supervised counterparts. Crucially, this is not a capability tradeoff: interpretability is uncorrelated with downstream task performance. What predicts it is the locality of the representation and its coarse-grained semantic alignment with humans, establishing interpretability as an independent, measurable dimension of representation quality.

Does human-alignment benefit interpretability?
How does aligning models with human perception reshape their representations, and does this improve interpretability? This work takes a first empirical step toward answering this question. Across three models from the DINO family, including one aligned with human fine-grained similarity judgments, we find that greater alignment is associated with greater interpretability, though sometimes at the cost of classification performance. More importantly, alignment reshapes not only the structure and functional properties of learned representations, but also the nature of their visual features — in the case of fine-grained similarity, promoting local features.
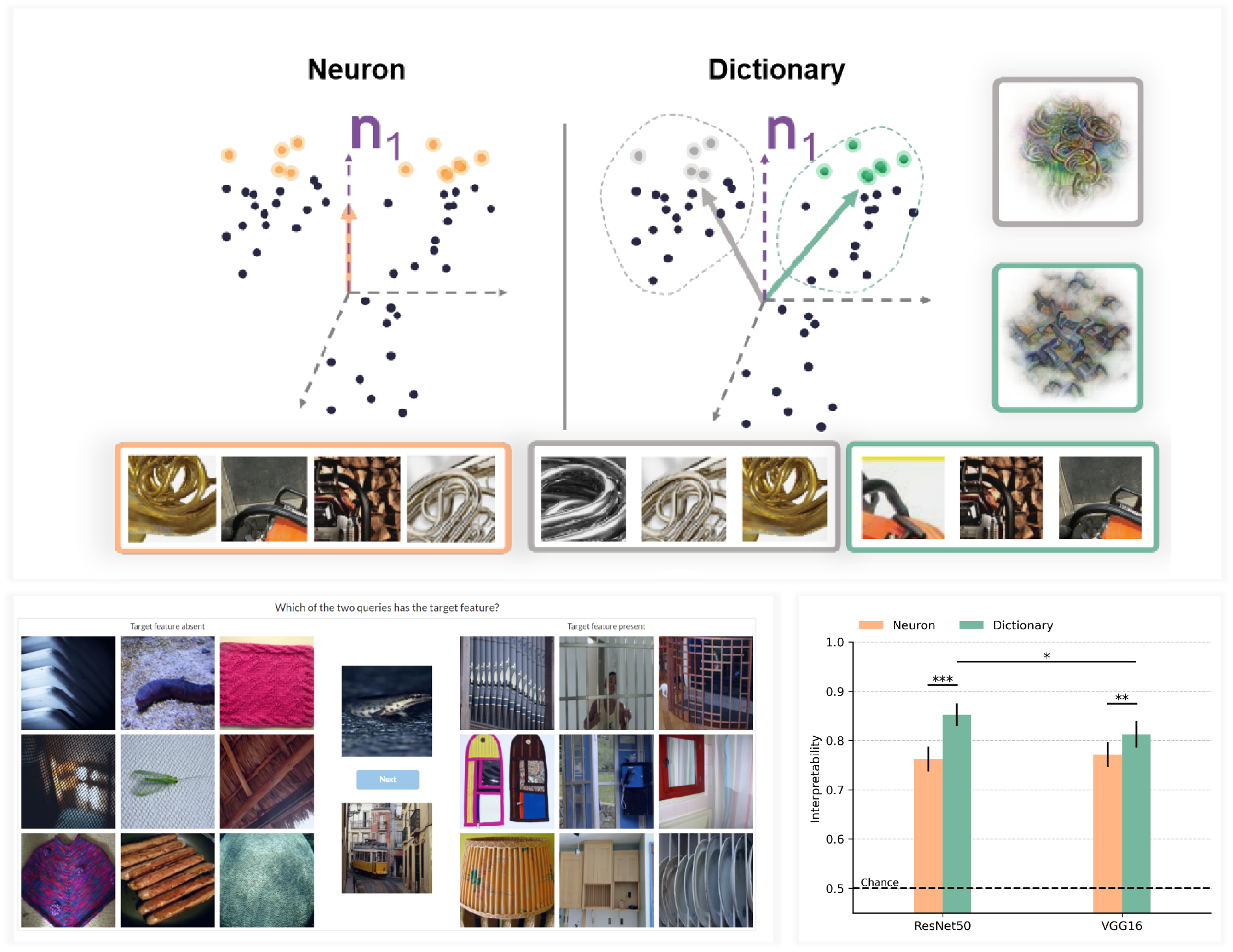
Choosing the right basis for interpretability: Psychophysical comparison between neuron-based and dictionary-based representations
What is the right "atom" for interpreting vision models? Neurons have long been the default, yet they often mix unrelated patterns—motivating a recent shift toward dictionary learning methods. Across 481 participants and 2 models, we measured how visually coherent features from neurons or dictionary elements are, and find (1) dictionary-based features consistently more interpretable, and (2) that comparing models using neurons alone can mask real differences and mislead conclusions.
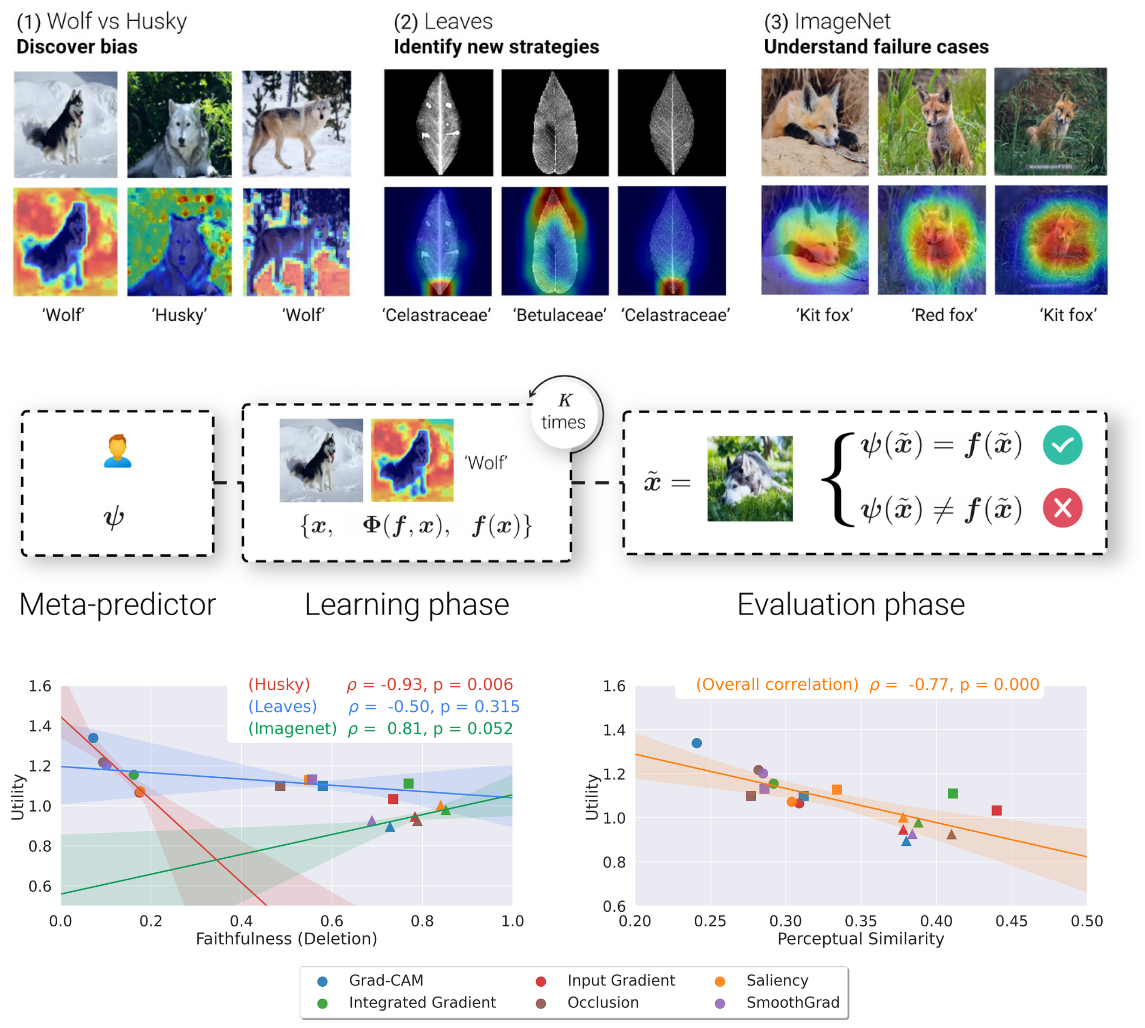
What i cannot predict, i do not understand: A human-centered evaluation framework for explainability methods
How useful are explainability methods for actual end-users? Most evaluation metrics for attribution methods have remained theoretical, with little regard for whether they help people understand AI systems. We address this gap with large-scale psychophysics experiments (n = 1,150) testing attribution methods across three real-world scenarios. Usefulness varies widely across scenarios, faithfulness metrics fail to predict practical utility, and high perceptual similarity between class-discriminative regions predicts failure cases — pointing to an intrinsic limitation of methods that show where but not what drives a decision.
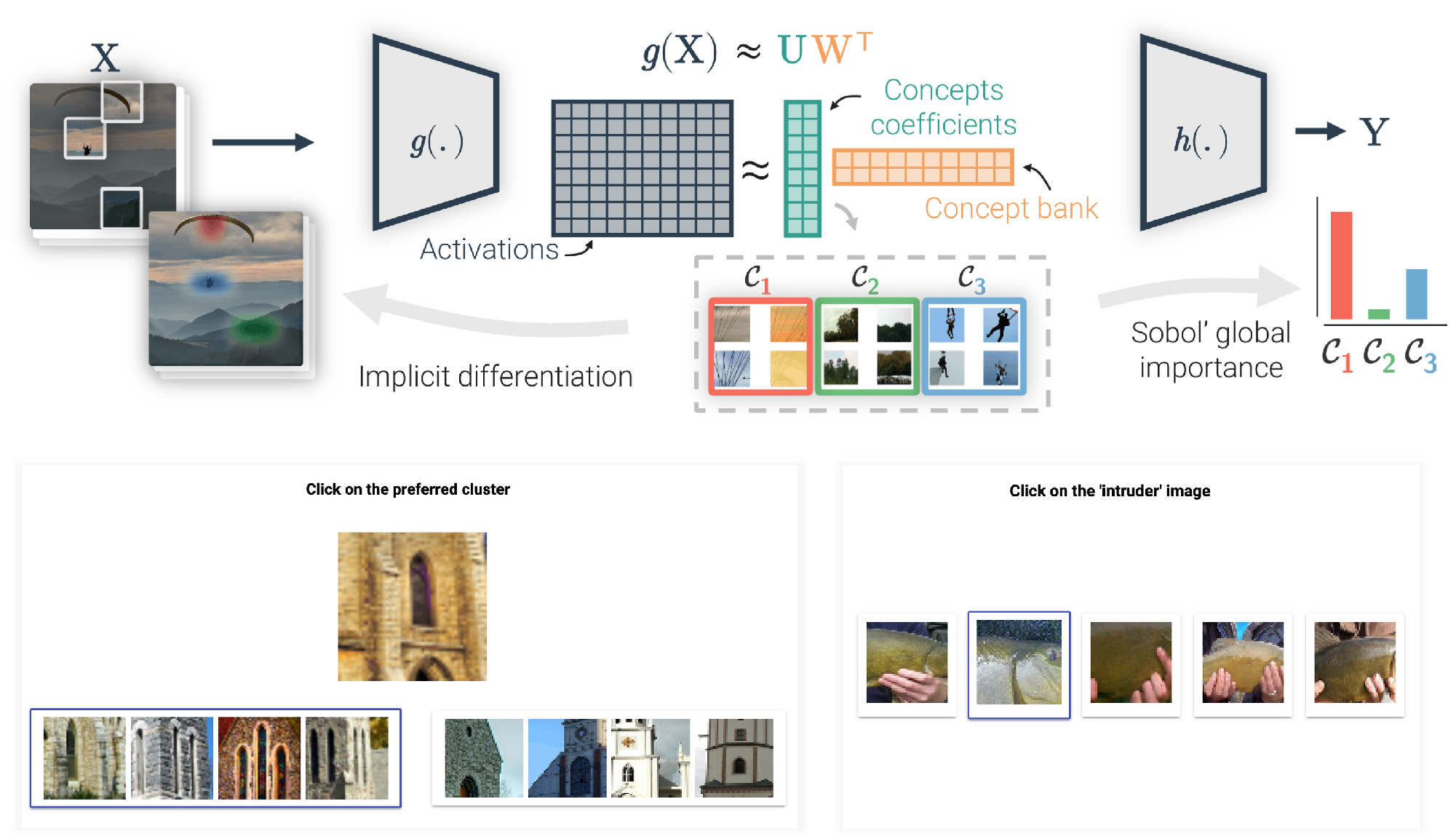
CRAFT: Concept Recursive Activation FacTorization for Explainability
Attribution methods reveal where a model looks but not what it sees there. We introduce CRAFT, a concept-based explainability method, that identifies both what and where, built on three ingredients: a recursive procedure that extracts concepts at the right level of granularity, a more faithful concept importance estimator using total Sobol indices, and implicit differentiation through NMF to produce concept attribution maps. Through extensive psychophysics experiments, we validate that CRAFT recovers human-interpretable concepts which help users predict model decisions better than standard attribution methods do.
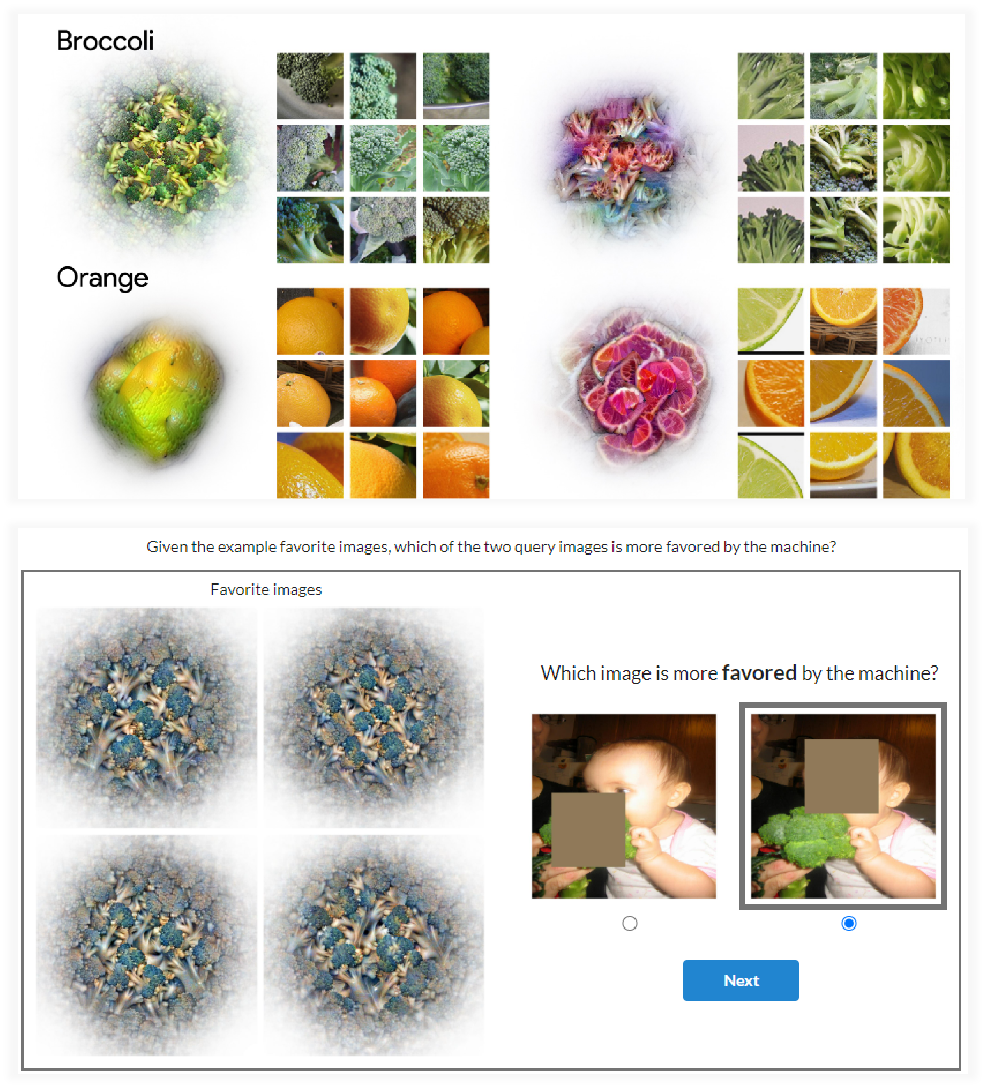
Unlocking feature visualization for deeper networks with magnitude constrained optimization
Feature visualization promises to reveal what a neuron responds to, but existing methods produce noisy images and fail to scale to modern architectures. We introduce MACO, a feature visualization method that optimizes only the phase of the Fourier spectrum while keeping its magnitude fixed — a constraint inspired by human vision, which relies primarily on phase to recognize objects. Through a human experiment, we show that MACO helps participants predict model activations better than prior methods, even on deep networks like ViT where existing approaches fail — unlocking interpretable feature visualizations for state-of-the-art networks without any learned image prior.